Lesson 5.3: Inference for Multiple Means Using ANOVA
Supplementary Notes 5.3
Baseball Batting Performance
Consider the example in Section 7.5.2 of the textbook that asks the question: Is batting performance related to player position in Major League Baseball (MLB)?
The data in bat18 [CSV file] includes batting records of 429 MLB players from the 2018 season who had at least 100 “at bats.” The variables in this study are:
OBP: on-base percentage, which is roughly equal to the fraction of times a player gets on base or hits a home run.position: the player’s primary field position (OF for outfield, IF for infield, C for catcher).
OBP is our response variable, y, in this study, and position is our explanatory group variable. Figure 1 has boxplots of OBP for each position:
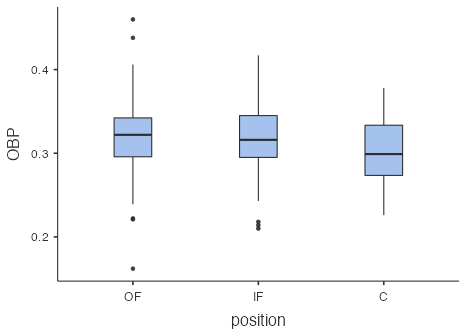
Figure 2 presents summary statistics of OBP for each position:
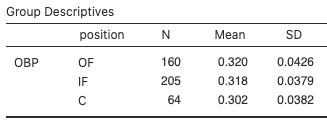
Based on the boxplot distributions (Fig. 1) and the summary statistics (Fig. 2), it looks like batting performance (as measured by OBP) is better for outfielders, then infielders, then catchers. We might wonder then if, based on this sample of players, we can conclude that the population mean OBP is higher for outfielders, then infielders, then catchers? However, there’s a fair bit of variability in y (OBP) within each group (position), so statistically we need to ask whether there is sufficient variation in the sample group means relative to the sample variation of y within each group to conclude there is a difference in the population group means.
We answer this question using a technique called Analysis of Variance (ANOVA), which uses a new family of models called F models.
F Models
F models, like the chi-square models introduced in Supplementary Notes 4.2, only take positive values and are skewed to the right. They use a probability distribution called the F-distribution that has two degrees of freedom numbers:
- df1 is called the numerator degrees of freedom.
- df2 is called the denominator degrees of freedom.
Analysis of Variance (ANOVA)
Here’s how to conduct Fisher’s ANOVA F-test to compare population means in k groups.
Hypotheses
- H0: The mean response is the same across all k groups, i.e.,
 .
. - HA: At least two means are different.
Conditions
- Independence: The observations are independent within and between groups.
- Nearly Normal Condition: The observations within each group are nearly normal. If the observations are highly non-normal, then use a Kruskal-Wallis test instead. (Details are beyond the scope of this course.)
- Variability: The variability within each group is approximately the same. If the within-group variability is too different, then use Welch’s ANOVA instead. (Details are beyond the scope of this course.)
Mechanics
- Use statistical software to obtain the test statistic,
 .
.
 is the mean square between groups and measures variability between the group means (
is the mean square between groups and measures variability between the group means ( ).
). is the mean square error and measures variability in y within the groups.
is the mean square error and measures variability in y within the groups.
- Use statistical software to obtain the p-value using the fact that under the null hypothesis,
 has an F-distribution with
has an F-distribution with  numerator degrees of freedom (df1) and
numerator degrees of freedom (df1) and  denominator degrees of freedom (df2).
denominator degrees of freedom (df2).
Decision Rule and Conclusion
- If the p-value is less than the significance level
 , then reject H0 in favour of HA and conclude that there is sufficient evidence that at least two population means are different.
, then reject H0 in favour of HA and conclude that there is sufficient evidence that at least two population means are different. - If the p-value is greater than the significance level , then fail to reject H0 in favour of HA and conclude that there is insufficient evidence that at least two population means are different.
Baseball Example
Hypotheses
- H0:
 .
. - HA: At least two means are different.
Conditions
- Independence: No obvious reason to doubt independence within and between groups.
- Nearly Normal Condition: The observations within each group appear to be nearly normal based on the points lying reasonably close to the lines in the following normal probability plots, with no extreme outliers.
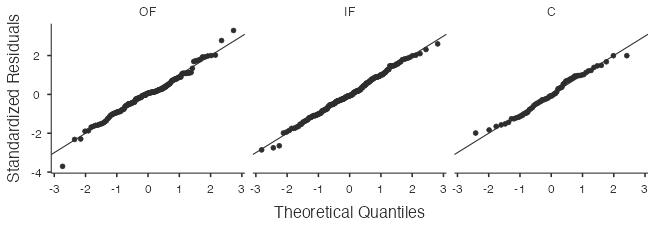
- Variability: The variability within each group is approximately the same based on the sample statistics reported above.
Mechanics
- From the jamovi software output (Fig. 4),
 .
. - The p-value based on the F-distribution with
 numerator degrees of freedom (df1) and
numerator degrees of freedom (df1) and  denominator degrees of freedom (df2) is 0.007.
denominator degrees of freedom (df2) is 0.007.
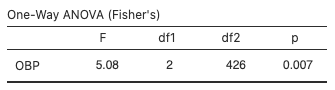
Decision Rule and Conclusion
The p-value 0.007 is less than the significance level  , so reject H0 in favour of HA and we conclude that there is sufficient evidence that at least two population means are different.
, so reject H0 in favour of HA and we conclude that there is sufficient evidence that at least two population means are different.
Alternatively, reject H0 in favour of HA if the test statistic is in the rejection region (greater than the critical value). Do not reject H0 if the test statistic is not in the rejection region (less than the critical value). The critical value in the baseball example is 3.0169, the 95th percentile of the chi-square distribution with two numerator degrees of freedom and 426 denominator degrees of freedom. Since the test statistic, F = 5.08 is greater than 3.0169, it is in the rejection region, so we reject H0 in favour of HA.
Multiple Comparisons
Having found evidence that at least two population means are different, we might be tempted at this point to use the two-sample t-tests from Lesson 5.2 to determine which means are different from each other. However, that would require multiple tests, each having a chance of leading to an incorrect decision (a Type 1 error), which leads to an excessive risk of concluding that two means are different when they’re really the same. For example, in the baseball example, if we were to do three t-tests each using , then the overall probability of concluding that two means are different when they’re really the same is  , which is considered unacceptably high.
, which is considered unacceptably high.
To mitigate this problem of multiple comparisons, we can try a few different post-hoc approaches, two of which are:
- Bonferroni correction for : Simply divide by the number of groups (k) and conduct the two-sample t-tests using
 and the pooled standard deviation based on all k groups. This approach is easy to apply, but it is not the most effective.
and the pooled standard deviation based on all k groups. This approach is easy to apply, but it is not the most effective. - Tukey’s range test (or Tukey’s HSD): The specifics of how this works lie beyond the scope of this course. All we need to know is that we can use statistical software to find adjusted p-values for all the pairwise comparisons.
Baseball Example
Bonferroni correction for : Conduct the two-sample t-tests using  .
.
- Compare OF to IF: t-statistic = 0.342, p-value = 0.7325 > 0.0167. Conclude not different.
- Compare OF to C: t-statistic = 3.04, p-value = 0.0025 < 0.0167. Conclude different.
- Compare IF to C: t-statistic = 2.89, p-value = 0.0040 < 0.0167. Conclude different.
Overall conclusion: The mean OBP for outfielders and infielders do not differ statistically, but both differ from the mean OBP for catchers.
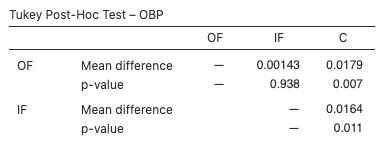
Tukey’s range test (Tukey’s HSD):
- Compare OF to IF: mean difference = 0.00143, adjusted p-value = 0.938 > 0.05. Conclude not different.
- Compare OF to C: mean difference = 0.0179, adjusted p-value = 0.007 < 0.05. Conclude different.
- Compare IF to C: mean difference = 0.0164, adjusted p-value = 0.011 < 0.05. Conclude different.
Overall conclusion: The mean OBP for outfielders and infielders do not differ statistically, but both differ from the mean OBP for catchers.